BYOC的全称是Bring You Own Codegen,也就是自定义代码生成。BYOC的输入为Relay图,也就是输入框架经过翻译后成为高层的语言。而输出取决与硬件方提供的编译器环境,可以是c语言、CUDA、JSON等。但是通过阅读官方文档可以发现,并没有生成LLVM IR的说法,因此通过BYOC生成LLVM IR有待商榷。
下面通过TVM官方的How to Bring Your Own Codegen的例子,来说明BYOC的pipeline。
运行时 开发者还可能需要实现一个运行时来初始化自己的图引擎并且执行编译的函数。在推断期间,当TVM运行时遇到相应的功能调用时,TVM运行时会利用自定义的运行时来调用卸载功能。Your runtime is responsible for launching the compiled function with the given input tensor arrays and filling in the results to the output tensor arrays.
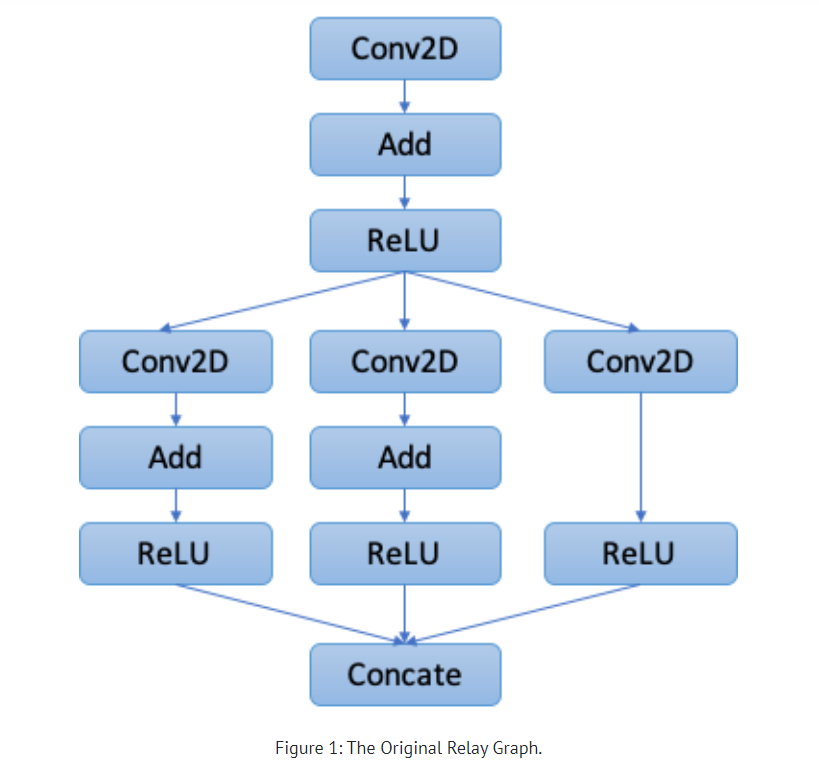
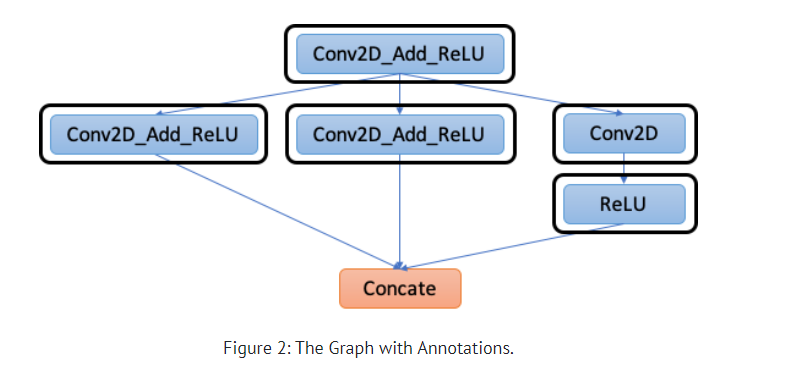
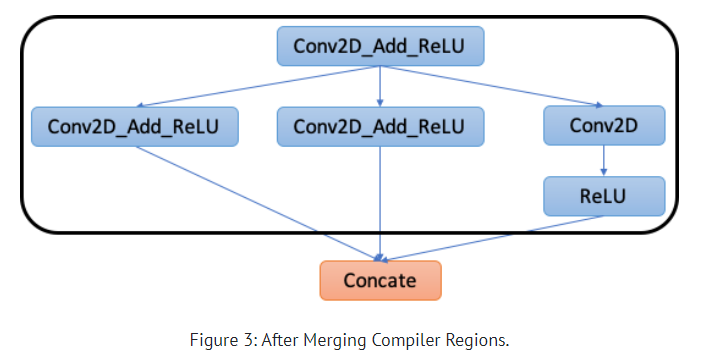
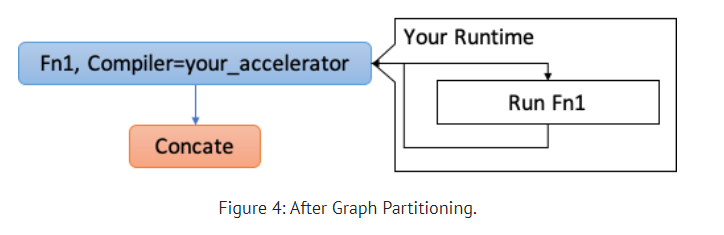
mod = create_relay_module_from_model() # Output: The Original Relay Graph mod = transform.MergeComposite(pattern_table)(mod) mod = transform.AnnotateTarget(["dnnl"])(mod) # Output: The Graph with Annotations mod = transform.MergeCompilerRegions()(mod) # Output: The Graph after merging compiler regions mod = transform.PartitionGraph()(mod) # Output: The Graph After Graph Partitioning
classDNNLModuleCodegen : public CSourceModuleCodegenBase { public: // Create a corresponding DNNL function for the given relay Function. std::pair<std::string, Array<String>> GenDNNLFunc(const Function& func) { ... }
/*! * \brief The overridden function that will create a CSourceModule. In order * to compile the generated C source code, users need to specify the paths to * some libraries, including some TVM required and dnnl specific ones. To make * linking simpiler, the DNNL kernels are wrapped in a TVM compatible manner * and live under tvm/src/runtime/contrib/dnnl folder. * * \param ref An object ref that could be either a Relay function or module. * * \return The runtime module that contains C source code. */ runtime::Module CreateCSourceModule(const ObjectRef& ref)override{ // Create headers code_stream_ << "#include <cstdint>\n"; code_stream_ << "#include <cstdlib>\n"; code_stream_ << "#include <cstring>\n"; code_stream_ << "#include <vector>\n"; code_stream_ << "#include <tvm/runtime/c_runtime_api.h>\n"; code_stream_ << "#include <tvm/runtime/container.h>\n"; code_stream_ << "#include <tvm/runtime/packed_func.h>\n"; code_stream_ << "#include <dlpack/dlpack.h>\n"; // dnnl_kernel file is saved under src/runtime/contrib/dnnl so that we don't // expose it to ordinary users. To make export_library use it, users need to // pass -I${PATH_TO_TVM}/src/runtime/contrib code_stream_ << "#include <dnnl/dnnl_kernel.h>\n"; code_stream_ << "using namespace tvm::runtime;\n"; code_stream_ << "using namespace tvm::runtime::contrib;\n"; code_stream_ << "\n";
// "ref" should be the paritioned Relay function with kCompiler=dnnl. CHECK(ref->IsInstance<FunctionNode>()); auto res = GenDNNLFunc(Downcast<Function>(ref));
// "code" is the generated C code with DNNL APIs. std::string code = code_stream_.str(); // "res" is a tuple of constant weights (symbols, values). // All constant tensors will be serialzied along with the generated C code // when export_library is invoked. String sym = std::get<0>(res); Array<String> variables = std::get<1>(res);
// Create a CSource module constauto* pf = runtime::Registry::Get("runtime.CSourceModuleCreate"); CHECK(pf != nullptr) << "Cannot find csource module to create the external runtime module"; return (*pf)(code, "c", sym, variables); }
private: /*! * \brief The code stream that prints the code that will be compiled using * external codegen tools. */ std::ostringstream code_stream_; };
classDNNLModuleCodegen : public CSourceModuleCodegenBase { public: // Create a corresponding DNNL function for the given relay Function. std::pair<std::string, Array<String>> GenDNNLFunc(const Function& func) { CHECK(func.defined()) << "Input error: expect a Relay function.";
// Record the external symbol for runtime lookup. auto sid = GetExtSymbol(func);
CodegenDNNL builder(sid); auto out = builder.VisitExpr(func->body); code_stream_ << builder.JIT(out);
// Copy the final output to the corresponding buffer. std::memcpy(out0, buf_2, 4 * 4608); std::free(buf_0); std::free(buf_1); std::free(buf_2); }
// The wrapper function with all arguments in DLTensor type. extern"C"intdnnl_0_wrapper_(DLTensor* arg0, DLTensor* arg1, DLTensor* arg2, DLTensor* out0) {
// Cast all DLTensor to primitive type buffers and invoke the above // execution function. dnnl_0_(static_cast<float*>(arg0->data), static_cast<float*>(arg1->data), static_cast<float*>(arg2->data), static_cast<float*>(out0->data)); return0; }
// The TVM macro to generate TVM runtime compatible function "dnnl_0" // from our generated "dnnl_0_wrapper_". TVM_DLL_EXPORT_TYPED_FUNC(dnnl_0, dnnl_0_wrapper_);