CUDA编程模型
CUDA编程模型
CUDA,Compute Unified Device Architecture,计算同一设备架构。
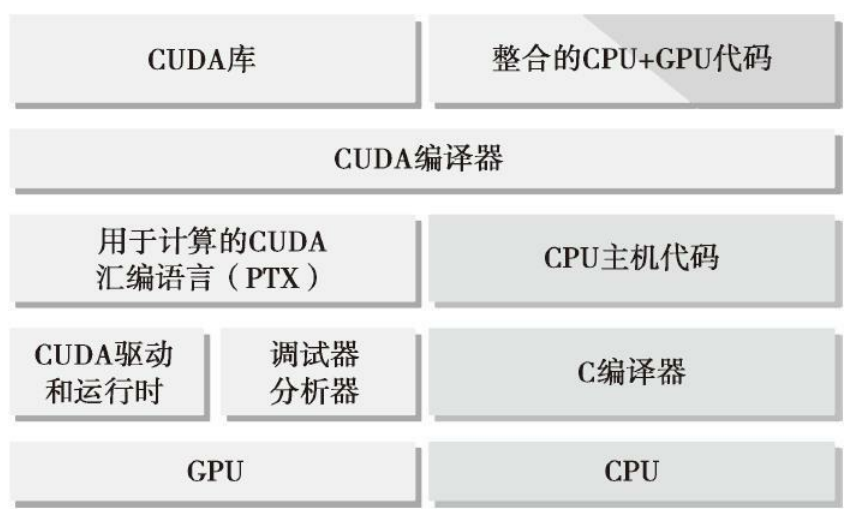
编程模型
编程模型指的是描述计算机程序中数据和算法之间交互的概念模型。通常包括程序的输入和输出、程序的组件以及它们之间的关系,以及程序的执行顺序和控制流程等方面。
例如面向对象编程模型是基于对象、类和继承等概念的模型,用于描述现实中的问题,使得程序的设计更为模块化和可拓展。
CUDA编程模型提供了一个计算机架构的抽象,作为应用程序和其可用硬件之间的桥梁。用于描述多个任务同时执行的计算机程序模型,在原有的并行编程模型的基础上,提供了以下两个特有功能:
- 通过层次结构在GPU中组织线程
- 通过层次结构在GPU中访问内存
CUDA编程模型使用由C语言扩展生成的注释代码在异构计算系统中执行应用程序。
在C语言并行编程中,需要使用pthreads或OpenMP技术来显式地管理线程。CUDA 提出了一个线程层次结构抽象的概念,以允许控制线程行为。这个抽象为并行编程提供了良好的可扩展性。
核函数
CUDA是异构程序框架,对于一份运行的本地代码文件而言,其代码中有一部分是运行在CPU上,一部分运行在GPU上,这样的编程逻辑叫Kernel编程。相对应的,代码中用于在GPU上运行的代码称为核函数(Kernel function)。
核函数是在CUDA平台上执行的函数,由关键字”__global__”修饰,可以在设备上运行,也能从主机端调用。核函数一般通过线程块和线程索引进行调用和执行,并且可以在CUDA内核中使CUDA特定的之类和语法来利用GPU硬件资源。
一个例子:
1 | __global__ void vectorAdd(float *a, float *b, float *c, int n) { |
NVIDIA GPU硬件结构
GPU架构是围绕着一个叫做流式多处理器(SM,Streaming Multiprocessors)可拓展阵列构建而成。并且对于不同的GPU而言,其SM的结构可能不一样,下面是Fermi GPU架构下的SM组成:

SM通常有下面几个部分组成:
- CUDA核心,又称SP(Streaming Processor)。一个SP可以执行一个thread,但是并不是所有的thread都可以在同一时刻执行。
- 共享内存/L1 缓存
- 寄存器文件
- 加载存储单元
- 特殊函数单元(Special Function Units)
- 线程束调度器(Warp Scheduler):
线程束:是SM中基本的执行单元。CUDA采用了SIMT架构来管理和执行线程,每32个线程为一组,称为线程束。线程束中的所有线程可以同时执行相同的指令,每个线程都有自己的地址计数器和寄存器状态。
GPU中每一个SM都可以支持数百个线程并发执行,每个GPU通常有多个SM,所以一个GPU可能并发执行数千个线程。当启动一个内核网络时,它的线程块被分布到了可用的SM上来执行。线程块一旦被调度到一个SM上,其中的线程只会在那个指定的SM上并发执行(多个线程块可能被分配到同一个SM上)。每个SM将分配它的线程块分到包含32个线程的线程束中。所有线程执行相同的指令,每个线程在私有数据上进行操作。
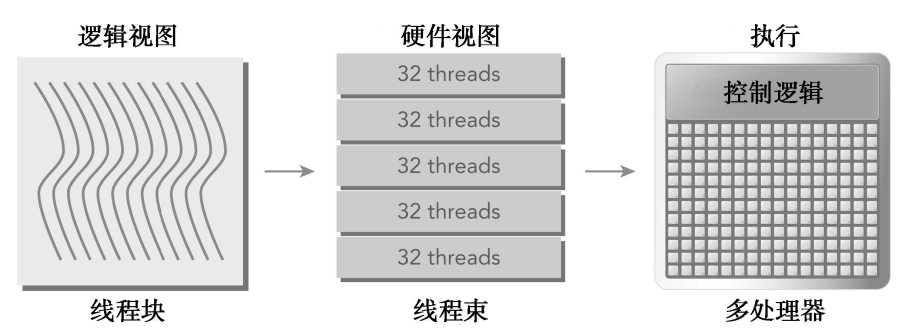
下面是CUDA编程中软件与硬件对应关系:
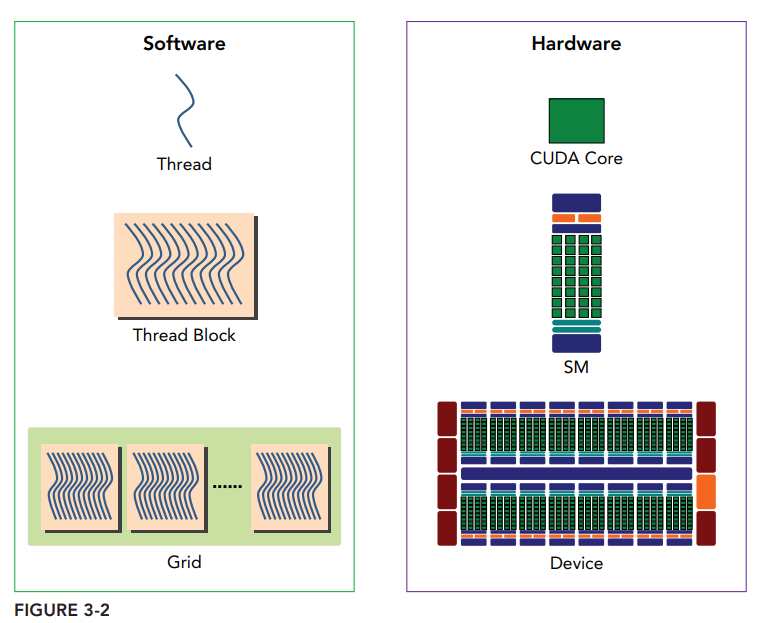
SIMT模型包含3个SIMD不具备的特征:
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
尽管线程块中所有线程可以逻辑地并行运行,但是并不是所有线程都可以同时在物理层面执行。因此,线程块里不同线程可能会以不同速度前进。
内存层次结构
CUDA内存模型提出了多种可编程内存的类型:
- 寄存器
- 共享内存 shared memory
- 本地内存 Local memory
- 常量内存 Constant memory
- 纹理内存 Texture memory
- 全局内存 Global memory
下图为这些内存空间的层次结构,每种内存都有不同的作用域、生命周期和缓存。
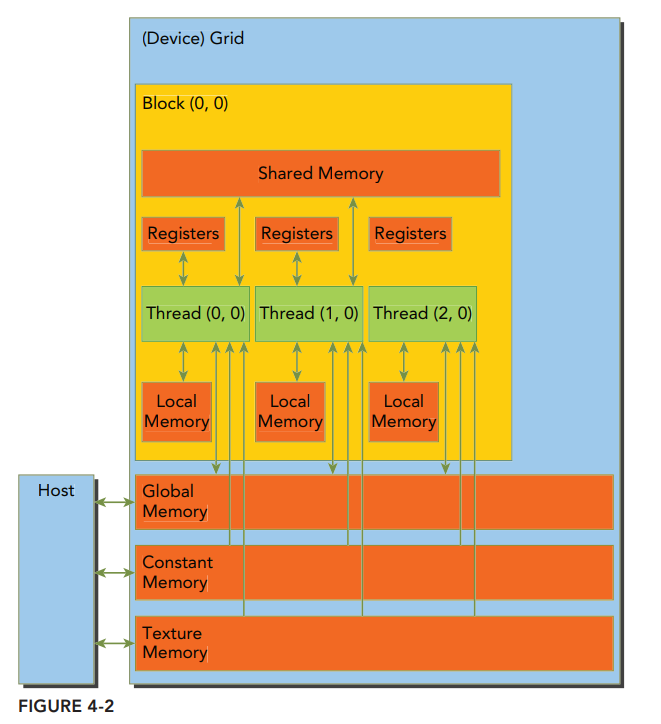
一个核函数中的线程都有自己私有的本地内存(Local Memory)。
一个线程块有自己的共享内存(Shared Memory),该内存对同一进程块中所有线程都可见,其内容持续线程块的整个生命周期。
所有线程都可以访问全局内存(Global Memory)。
所有线程都能访问的只读内存有:常量内存(Constant Memory)和纹理内存空间(Texture Memory)。纹理内存为各种数据分布提供了不同的寻址模式和滤波模式。
对于一个应用程序来说,全局内存、常量内存和纹理内存的内容具有相同的生命周期。
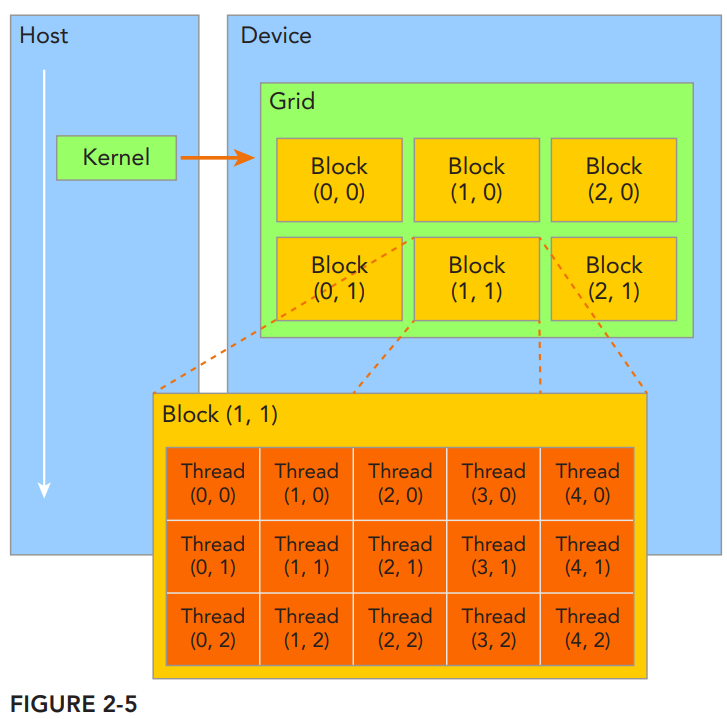
线程层次结构
CUDA通过对线程进行层次划分从而管理线程,该层次结构由线程块网络与线程块组成。
线程:操作系统系统调度的最小单元。在CUDA编程模型下每个线程都有自己的一个块内的线程索引threadIdx,以及一个线程块索引blockIdx。线程索引可以描述为0~3维空间。例如threadldx为(x, y)时,表示线程在线程块中呈二维分布,可以用(x, y)来确定线程的具体(二维)位置。可以用threadIdx.x, threadIdx.y, threadIdx.z来指定三个维度的字段。
通常用blockDim表示每个线程块中线程的数量,也就是最大容量。例如blockDim为(16, 16, 1)时表示每个线程块中包含了16*16个线程。
线程块:多个线程为一组,构成一个线程块。同一个线程块内部可以通过同步以及共享内存从而协作完成任务。描述线程块的变量为blockIdx,该变量可以描述为0~3维空间下的位置。例如blockIdx可以表示为(x, y, z),表示线程块在线程块网络中的”三维位置”。可以用blockIdx.x, blockIdx.y, blockIdx.z来指定三个维度的字段。
通常用gridDim表示一个线程块网络中启动的线程块的数量,例如(64,64,1)表示启动了64*64 = 4096个线程块。
线程块网络:一个线程块网络由多个线程块组成,这些线程块共享相同的全局内存空间。不同块内部的线程不能协作。
对于一个给定数据大小的情况,我们需要确定网络和块尺寸,一般步骤为:
- 确定线程块大小
- 在已知数据大小和块大小的基础上计算网络维度
在确定线程块大小时通常需要考虑:
- 内核的性能特性
- GPU资源限制
下面这段代码是构建一个2x1x1大小的数据块网格(grid)以及3x1x1大小的数据块(block),6个处理元素对应6个线程。
1 |
|
运行结果如下:
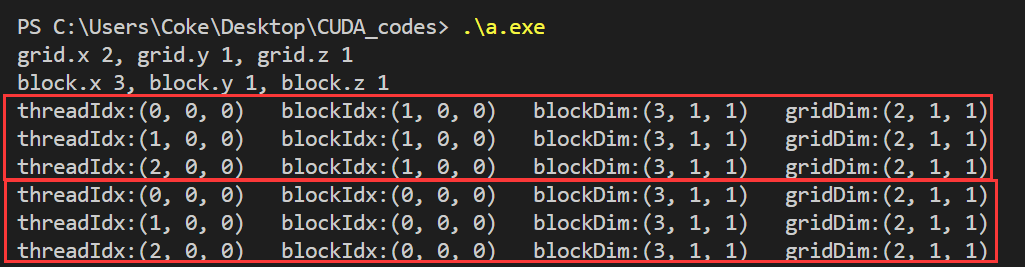
该结果是由6个线程打印得出,分别打印其线程索引,线程块索引,线程块维度,线程块维度。
使用块和线程建立索引
例子:计算矩阵加法
使用二维网络和二维线程块
使用一维网络和一维线程块
使用二维网络和一维线程块
CUDA编程模型结构
- 分配GPU内存
- 从CPU内存拷贝数据到GPU内存
- 调用CUDA内核函数来完成程序指定运算
- 将数据从GPU拷贝回CPU内存
- 释放GPU内存空间
CUDA编程模型
编程结构
在一个异构环境中包含多个CPU和GPU,每个GPU和CPU的内存都由一条PCI-Express总线分隔开。
主机内存:CPU及其内存
设备内存:GPU及其内存
从CUDA 6.0开始,NVIDIA提出了统一寻址的编程模型的改进,它连接了主机内存和设备内存空间,可以使用单个指针访问CPU和GPU内存,无需彼此拷贝数据。